
Struggling to make your digital content more engaging and accessible? Manually recording voiceovers is slow and expensive, creating a bottleneck that slows down marketers, creators, and developers. A Text to Speech API is the solution, acting as a specialized translator that turns written text into natural-sounding human speech. This guide breaks down how this technology works, its real-world applications, and what to look for when choosing the right API for your project, letting you add powerful voice features to any application without building a complex AI model from scratch.
What Is a Text to Speech API?
At its core, a Text to Speech (TTS) API solves a massive problem for creators and businesses alike: how to make digital content more accessible and engaging. Before this, you were stuck with the high costs and slow turnaround times of hiring voice actors or booking a recording studio. A text to speech API changes the game by automating this process, giving developers a simple way to integrate voice into their applications.
The shift towards this technology has been huge. The global TTS market is valued at around USD 4.0 billion in 2024 and is expected to rocket to USD 7.6 billion by 2029. That's not just growth; it's a fundamental change in how we interact with digital content.
This diagram gives you a peek under the hood at how speech synthesis works, showing the journey from plain text to a final audio waveform.
As you can see, the process involves converting text into a phonetic representation before an AI model generates the actual sound. A TTS API handles all this heavy lifting for you in seconds.
The API Bridge Explained
You can think of an API (Application Programming Interface) as a bridge connecting two different pieces of software so they can talk to each other. In this case, it connects your app to a powerful speech synthesis engine.
The whole exchange is surprisingly simple:
- You send a request: Your app bundles up a piece of text and sends it over to the API.
- The AI gets to work: The provider's engine instantly analyzes the text, paying close attention to grammar, punctuation, and context to get the intonation just right.
- Speech is created: It generates a crisp, clear audio file based on the voice, language, and other settings you picked.
- You get the audio back: The API sends the finished audio file back to your app, ready to be played for your user.
This elegant back-and-forth makes it incredibly easy to add voice features to websites, mobile apps, and all kinds of digital products. For a deeper dive into the basics, this Text to Speech overview is a great resource.
It’s no surprise that these APIs are the engine behind many of the best AI tools for content creation on the market today.
How a TTS API Translates Text into Voice
Have you ever wondered how a machine turns a string of text into a voice that sounds genuinely human? A text to speech API does a lot more than just read words out loud. It’s a sophisticated, multi-step process that intelligently interprets and vocalizes text, bridging the gap between robotic narration and a lifelike performance. It all starts with what’s known as text preprocessing. Before a single sound is made, the AI has to actually understand the text it's been given—not just the letters, but the context and structure.
Stage 1: Text Preprocessing
Think of this first phase as the AI acting like a meticulous editor. Its job is to clean up the raw text, resolving any ambiguities that could trip up the voice synthesis later on. It's all about prepping the text for a smooth, natural delivery.
Here’s what happens behind the scenes:
- Expanding Abbreviations: It figures out that "Dr." should be spoken as "Doctor" and that "St." might mean "Street" or "Saint," depending on the surrounding words.
- Interpreting Numbers: The API knows that "1999" should be read as "nineteen ninety-nine" and "$50" as "fifty dollars." This is crucial for sounding natural.
- Analyzing Punctuation: A comma tells the voice to take a short breath. A question mark lifts the intonation at the end of a sentence. An exclamation point adds a little punch.
This normalization step ensures the text is phonetically clear and ready for the next stage, setting the foundation for an accurate performance.
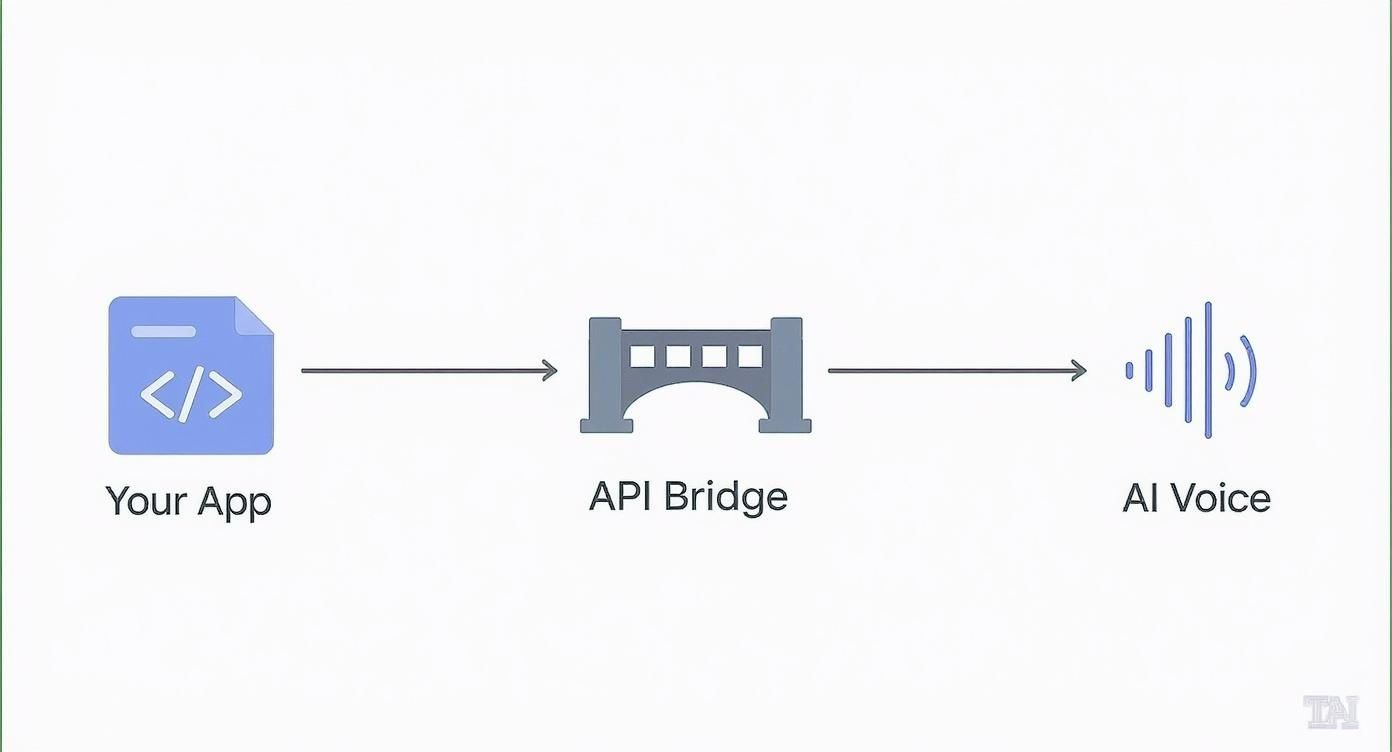
As you can see, the connection is straightforward but powerful. Your app sends the text, the API acts as the go-between, and the AI voice model gets to work on the heavy lifting.
Stage 2: Speech Synthesis
With the text cleaned up and ready to go, the real magic begins. This is where a neural network—an AI model trained on thousands of hours of human speech—takes over. Imagine an AI actor that has studied countless vocal performances to learn the tiny details of human expression. This model doesn’t just string sounds together. It generates prosody—the rhythm, stress, and intonation that make speech sound human. It learns where to pause naturally, which words to emphasize, and how to create a cadence that flows. Today’s neural TTS systems are light-years ahead of the monotone, robotic voices you might remember. They can capture emotional nuance, making the final audio far more engaging and believable.
Stage 3: Audio Generation
The final step is to turn all that linguistic and prosodic information into an actual sound file. This is where the abstract patterns and rules from the synthesis stage become a concrete digital audio waveform. This waveform is basically a map of sound vibrations. The AI builds this map with incredible precision, making sure the pitch, volume, and timing all match the patterns decided in the previous stage. The result? A high-quality audio file, like a WAV or MP3, that the API sends back to your app, ready to be played for your users.
What to Look For in a Modern TTS API
Diving into the world of Text-to-Speech APIs can feel like a lot to take in. With so many options out there, it’s easy to get lost. But the truth is, not all services are created equal, and the features you choose will make or break your user's listening experience. Will your audio sound natural and engaging, or will it fall flat with that all-too-familiar robotic drone? Let's break down the core features that separate the best from the rest. A truly modern TTS API isn't just about turning text into sound; it's about creating audio that's almost impossible to distinguish from a human speaker.
Key Features of a High-Quality TTS API
- Voice Quality and Naturalness: This is the most important feature. Top-tier APIs use advanced neural networks that capture the subtle rhythms, emotional tones, and natural pauses (prosody) that make a voice feel real. When testing, listen for clarity, natural intonation, and conversational pacing.
- Language and Accent Variety: To connect with a global audience, you need a diverse library of languages and regional accents. This makes content feel personal and familiar, whether a user is in London, Tokyo, or Mexico City. For marketers and creators, this is key to localization.
- Customization and Control: Real creative power comes from directing the vocal performance. Look for support for Speech Synthesis Markup Language (SSML), which lets you embed tags in your text to control speed, pitch, volume, and add pauses for dramatic effect.
- Performance and Scalability: Your API must be reliable. Look for providers guaranteeing high uptime (99.9%+) and low latency for a snappy, real-time user experience. This ensures your service doesn't falter during traffic spikes.
This table gives you a quick cheat sheet for what to expect. If you're just starting, the "Basic" column is a great baseline. But for professional, high-impact projects, you’ll want to look for the features in the "Advanced" column to really make your audio stand out.
| Feature | What to Look For (Basic) | What to Look For (Advanced) |
|---|---|---|
| Voice Quality | Clear, understandable standard neural voices. | Ultra-realistic, emotionally expressive voices with nuanced intonation. |
| Languages & Accents | Support for major global languages (e.g., English, Spanish, Mandarin). | A massive library of 20+ languages and multiple regional accents for each. |
| Customization | Basic controls for speed (rate) and volume. | Full SSML support for fine-tuning pitch, pauses, emphasis, and phonetics. |
| Voice Cloning | No voice cloning or pre-set voices only. | Ability to create a custom digital replica of a specific voice (voice cloning). |
| API Performance | Standard latency, suitable for non-real-time applications. | Low-latency, real-time streaming for interactive use cases like voice bots. |
Real-World Use Cases for a Text to Speech API
The real magic of a text to speech API isn't just in the code—it's in the real-world problems it solves for marketers, creators, and businesses. This technology is quietly changing how we all interact with digital information, making content more accessible, engaging, and just plain easier to consume. From giving a voice to the voiceless to helping creators produce captivating media, the uses are as practical as they are profound. Let's dive into some of the most impactful ways TTS APIs are making a difference right now.

Enhancing Accessibility for All Users
Perhaps the most important job for TTS is making the digital world accessible. For millions of people with visual impairments, a text to speech API is their bridge to online content. These APIs are the engine behind essential tools like screen reader technology, which reads aloud everything from websites and articles to app interfaces. This isn't just a convenience; it's about digital inclusion. It's also a powerful tool for those with learning disabilities like dyslexia, offering an alternative way to consume information.
Powering Modern Content Creation
For content creators and marketing agencies, a text to speech API is a game-changer. Recording voiceovers is slow and expensive, but TTS provides an instant, high-quality alternative.
- Video Narration: Generate a professional voiceover for YouTube tutorials, training videos, or social media ads in minutes.
- Podcast Production: Create entire podcasts from a script or add AI-voiced segments for news updates.
- Audiobook Creation: Indie authors can turn their e-books into audiobooks affordably, reaching a massive audience of listeners.
- Interactive Articles: Embed an audio version of a blog post on the page to let users listen on the go, boosting engagement and time on page.
By automating voice production, creators can produce more content, faster, and for a fraction of the cost. Need more inspiration? Check out our guide on how to use AI for marketing.
Improving Customer Experience and Education
In customer service, TTS APIs are making automated phone systems less robotic. Companies can use dynamic, AI-generated voices for personalized updates, such as order statuses or appointment reminders, creating a smoother and more professional experience. In education, e-learning platforms use TTS to voice lessons and digital textbooks, which is a massive help for auditory learners and students with reading difficulties.
Getting Started: How to Integrate a Text to Speech API
So, you're ready to give your project a voice? Great. The good news is that plugging a text to speech API into your app is almost always less intimidating than it sounds. You don't need to be a machine learning expert to get this done. Most of the heavy lifting is handled by the API provider, leaving you to focus on creating a great user experience. Let's break down the typical steps. While the specifics will vary a little from one provider to another, the general game plan is remarkably consistent.
Step 1: Choose a Provider and Get Your API Key
First, you need to choose your API based on your project's needs—are you looking for the most realistic voice, the widest language support, or the best price? Once you’ve picked one, sign up and get your API key from their developer dashboard. Think of this key as the secret password between your application and the API. It authenticates your requests and allows the provider to track your usage for billing. Treat this key with care and never expose it in your front-end code.
Step 2: Make the API Call
This is where the magic happens. You’ll send an HTTP request to the provider's server, including your text, API key, and any other parameters like the desired voice, speaking rate, or audio format. Most providers have excellent documentation with code snippets for popular languages like Python, JavaScript, or Java. For example, a simple request using Python might look like this:
import requests
# Your secret API key
api_key = "YOUR_SECRET_API_KEY"
headers = {"Authorization": f"Bearer {api_key}"}
# The data for your request
data = {
"text": "Hello, world! This is my first audio generation.",
"voice": "en-US-Standard-A" # A specific voice model
}
# Sending the request to the provider's endpoint
response = requests.post("https://api.provider.com/v1/tts", headers=headers, json=data)
# If successful, save the audio file
if response.status_code == 200:
with open("output.mp3", "wb") as f:
f.write(response.content)
If you're looking to get more comfortable with this kind of interaction, checking out various machine learning code examples can be a huge help.
Step 3: Handle the Response
After the API works its magic, it sends back an audio file. Now it's your application's job to do something with it. You can save it to your server, stream it directly to the user's browser, or embed it in an on-page audio player. The key takeaway is to rely on your provider's documentation—it is your best friend during integration.
👉 Try MediaWorkbench.ai for free – schedule your posts and generate AI content in one place!
Conclusion
A text to speech API is far more than a technical tool; it's a bridge to more engaging, accessible, and efficient content creation. By converting text into lifelike audio, this technology empowers marketers, creators, and developers to reach wider audiences, improve user experience, and automate workflows that were once slow and costly. From powering accessible web content to generating professional voiceovers for videos and podcasts, the applications are limitless. When choosing an API, remember to prioritize voice quality, customization options, and scalability to ensure you're building on a solid foundation.
Ready to give your content a voice that captivates? Media Workbench AI offers a full suite of advanced AI content creation tools, including top-tier text-to-speech generation. Explore our platform and discover how easy it is to add professional-grade audio to your projects.

